Member-only story
New State of the Art AI Optimizer: Rectified Adam (RAdam). Improve your AI accuracy instantly versus Adam, and why it works.
A new paper by Liu, Jian, He et al introduces RAdam, or “Rectified Adam”. It’s a new variation of the classic Adam optimizer that provides an automated, dynamic adjustment to the adaptive learning rate based on their detailed study into the effects of variance and momentum during training. RAdam holds the promise of immediately improving every AI architecture compared to vanilla Adam as a result:
I have tested RAdam myself inside the FastAI framework, and quickly achieved new high accuracy records versus two of the hard to beat FastAI leaderboard scores on ImageNette. Unlike many papers I have tested this year where things only seem to work well on their specific datasets used in the paper, and not so well on new datasets I try it with, it appears RAdam is a true improvement and likely to be the permanent successor to vanilla Adam imo.


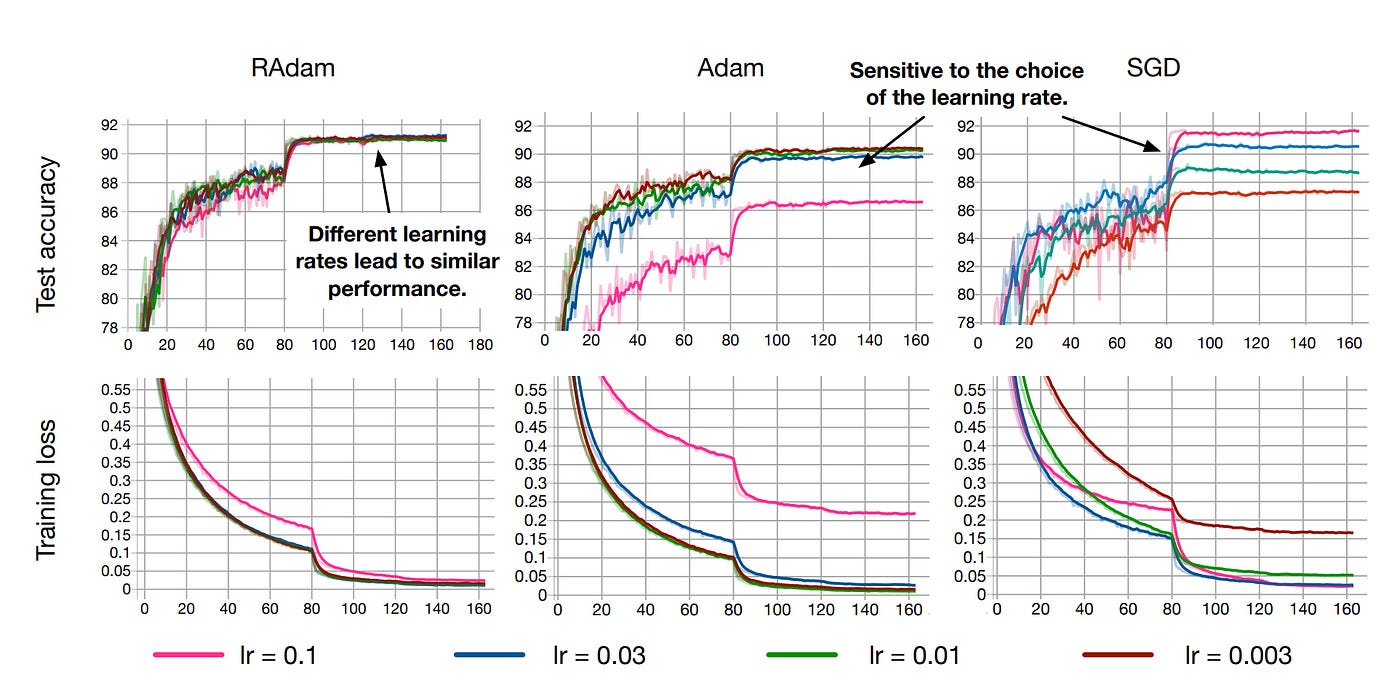
Thus, let’s delve into RAdam and understand what it does internally, and why it holds the promise of delivering improved convergence, better training stability (much less sensitive to chosen learning rates) and better accuracy and generalization for nearly all AI applications.

The goal for all AI researchers — a Fast and Stable Optimization algorithm…
The authors note that while everyone is working towards the goal of having fast and stable optimization algorithms, adaptive learning rate optimizers including Adam, RMSProp, etc. all suffer from a risk of converging into poor local optima — if a warm-up method is not implemented. Thus, nearly everyone uses some form of warmup (FastAI has a built in warmup in it’s Fit_One_Cycle)…but why is a warmup needed?