Member-only story
Meet Mish — New State of the Art AI Activation Function. The successor to ReLU?
A new paper by Diganta Misra titled “Mish: A Self Regularized Non-Monotonic Neural Activation Function” introduces the AI world to a new deep learning activation function that shows improvements over both Swish (+.494%) and ReLU (+ 1.671%) on final accuracy.
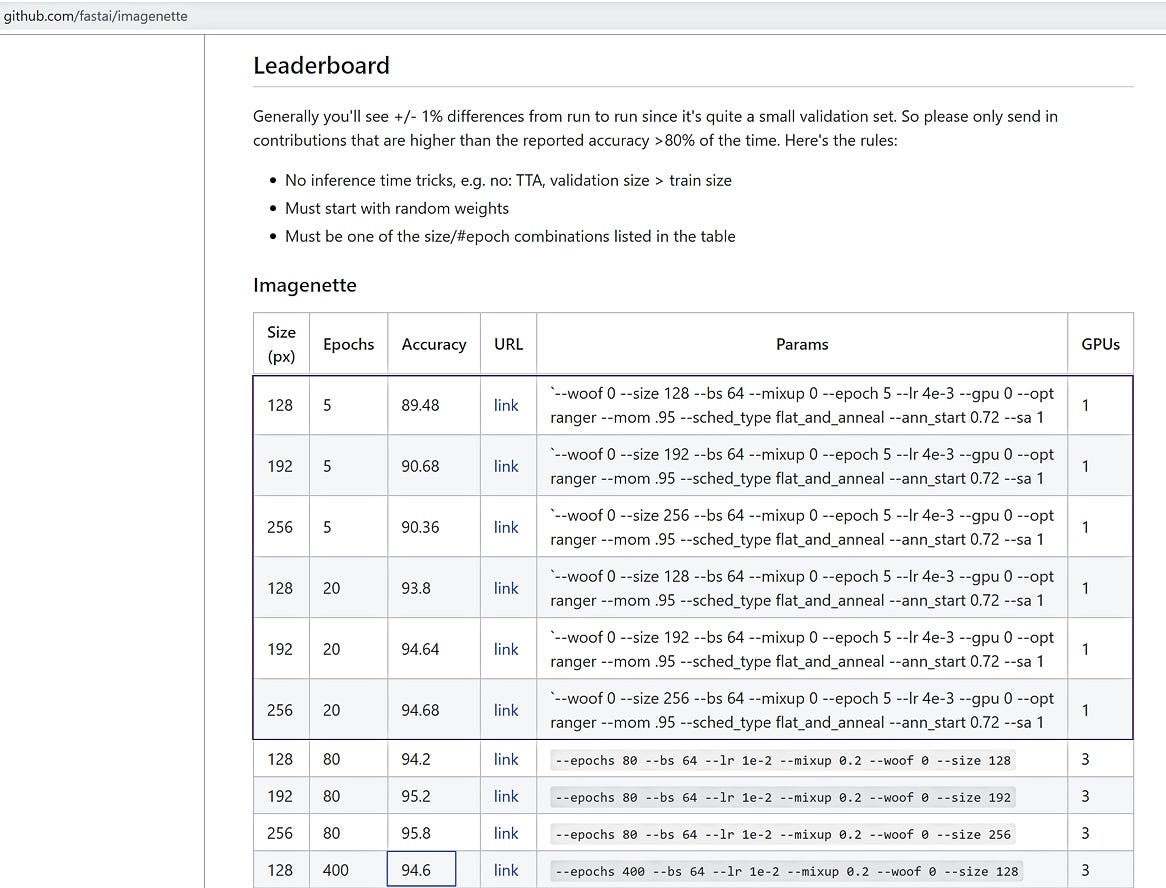
Our small FastAI team used Mish in place of ReLU as part of our efforts to beat the previous accuracy scores on the FastAI global leaderboard. Combining Ranger optimizer, Mish activation, Flat + Cosine anneal and a self attention layer, we were able to capture 12 new leaderboard records!
As part of our own testing, for 5 epoch testing on the ImageWoof dataset, we can say that:
Mish beats ReLU at a high significance level (P < 0.0001). (FastAI forums, @ Seb)
Mish has been tested on over 70 benchmarks, ranging from Image Classification, Segmentation and Generation and compared against 15 other activation functions.



I made a PyTorch implementation of Mish, dropped it in for ReLU with no other changes and tested it with a broad spectrum of optimizers (Adam, Ranger, RangerLars, Novograd, etc) on the difficult ImageWoof dataset.
I found Mish delivered across the board improvements in training stability, average accuracy (1–2.8%) and peak accuracy (1.2% — 3.6%), matching or exceeding the results in the paper.
Below is Ranger Optimizer + Mish compared to the FastAI leaderboards:

