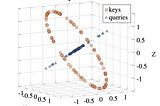
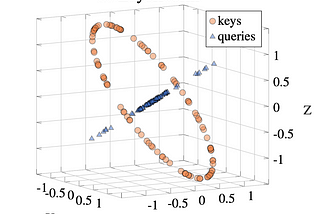
Less WrightWhat LayerNorm really does for Attention in Transformers2 things, not 1…May 14, 20232May 14, 20232
Less WrightSculpted shoulders — the best exercise for the rear deltsBuilding from the V shaped physique concept, you need to also have depth from the side view. This is achieved by building the ‘rear delts’…Jul 11, 20211Jul 11, 20211
Less WrightAchieving V shaped physique — the optimal shoulder exercise to add shoulder widthExercising your side delts can add impressive width, but one exercise gives you the best bang for the buck.Jul 5, 20212Jul 5, 20212
Less WrightA working, evidence based theory on the origins of Covid-19: hint, mice with human lung tissue…Genetically modified mice with ‘humanized lungs’ were apparently created to test the infectiousness of coronaviruses in Summer, 2019 and…Jun 4, 20212Jun 4, 20212
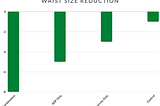
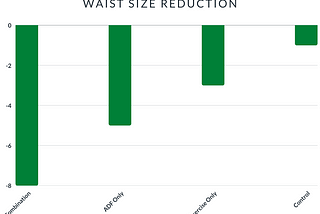
Less WrightRapid fat loss, keep the muscle— has the optimal combo of diet and exercise been found?Combining intermittent fasting days with cardio = Double the fat loss, retain muscle mass, improve cholesterol…Jun 1, 20218Jun 1, 20218
Less WrightBuilding Bigger Biceps — 4 science based tips that can maximize your results.Four tips from scientific studies point the way to maximizing your gains if you are interested in increasing your arm size as efficiently…Jan 4, 2021Jan 4, 2021
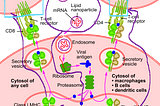
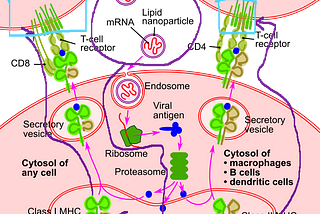
Less WrightSummary info on how the new mRNA Covid-19 vaccines (Pfizer, Moderna) work— no DNA reprogramming…Short summary of how the US approved mRNA Covid vaccines work (Pfizer, Moderna)Dec 27, 2020Dec 27, 2020
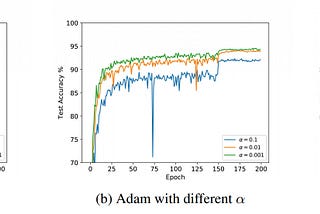
Less WrightMeet AdaMod: a new deep learning optimizer with memoryAdaMod is a new deep learning optimizer that builds on Adam, but provides an automatic warmup heuristic and long term learning rateJan 5, 20205Jan 5, 20205
Less WrightMeet DiffGrad: New Deep Learning Optimizer that solves Adam’s ‘overshoot’ issueDiffGrad, a new optimizer introduced in the paper “diffGrad: An optimizer for CNN’s” by Dubey, et al, builds on the proven Adam optimizerDec 26, 20193Dec 26, 20193
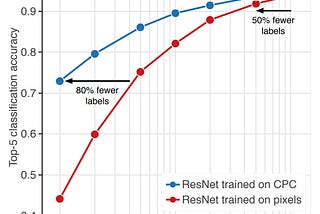
Less WrightReducing your labeled data requirements (2–5x) for Deep Learning: Google Brain’s new “ContrastiveCurrent Deep Learning for vision, audio, etc. requires vast amounts of human labeled data, with many examples of each category, to properlyDec 16, 2019Dec 16, 2019